
tg-me.com/knowledge_accumulator/77
Last Update:
RL в квадрате [2016] - учим RL-алгоритм с помощью RL-алгоритма
Я в последнее время часто думаю о том, о чём говорил в посте выше - как нам обучить, а не спроектировать, алгоритм, который быстро обучается? Ближе всего из разделов ML к этому вопросу находится Meta Learning, и сегодня я бы хотел рассказать про одну из известных статей в этой области.
Чего мы хотим добиться? Мы хотим получить систему, которая быстро аккумулирует опыт и начинает круто работать на новой задаче. В отличие от этого, в классическом RL нас просто волнует производительность в конкретной среде.
Как ни странно, на самом деле между этими постановками достаточно маленькая разница.
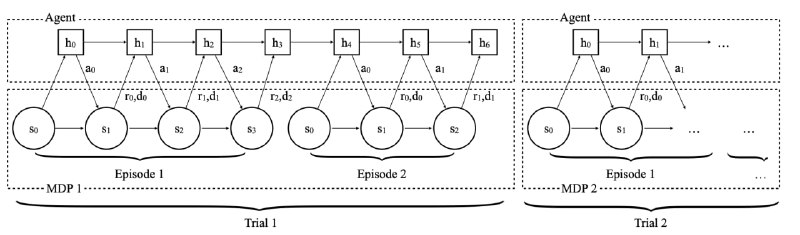
1) При обучении мета-алгоритма у нас есть некое семейство задач, из которого мы сэмплируем при обучении. При этом, на самом деле, это семейство можно воспринимать как одну задачу, но со случайной скрытой различающейся динамикой.
2) Для того, чтобы перейти от производительности к обучаемости, нам надо всего лишь стереть грани между эпизодами. В этом случае мы будем учиться оптимизировать не только награду в течение текущего эпизода, но и в будущих эпизодах, то есть мы учимся в том числе и исследовать среду ради выгоды в следующих попытках. А в качестве входа алгоритм будет обрабатывать не только историю траектории в текущей попытке, но и весь полученный в прошлом опыт. Новые границы "эпизодов" теперь будут лежать между разными задачами.
В итоге весь подход статьи сводится к одному изменению поверх обычного RL - к стиранию границ между эпизодами. Эта абсурдная простота лично мне давит на мозг. Это заставляет задуматься - что такое на самом деле обучаемость? Как нам добиться именно адаптируемости к новому, а не учиться делать вообще всё одной моделью? Как именно человеческий мозг пришёл к этому? У меня есть всего лишь догадки, но про них как-нибудь в другой раз...
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/77